
- Thu 18 November 2021
- algorithms
- Sitala
- #clustering, #jupyter, #python, #dbscan, #bind
Описание алгоритма кластеризации из книги Advanced Algorithms and Data Structures Final Release 2021 by Marcello La Rocca
Page 420, Section 12.3.2 От определений к алгоритму
Переход от определений к алгоритму на удивление простой.
Для данной точки p нам необходимо проверить как много соседей не попадает в радиус заданный ** \(\epsilon\) . Если их больше опеределенного количества m то мы отмечаем p** как базовую точку и добавляем его соседей в тот же самый кластер; в противном случае, неважно, мы ничего не делаем. Рисунок 12.10 илюстрирует этот шаг, который будет повоторятся для каждой точки набора данных, с помощью набора для отслеживания точек, которые мы хотим обработать в следующий раз (в любом порядке) для текущего кластера.
Рисунок 12.10
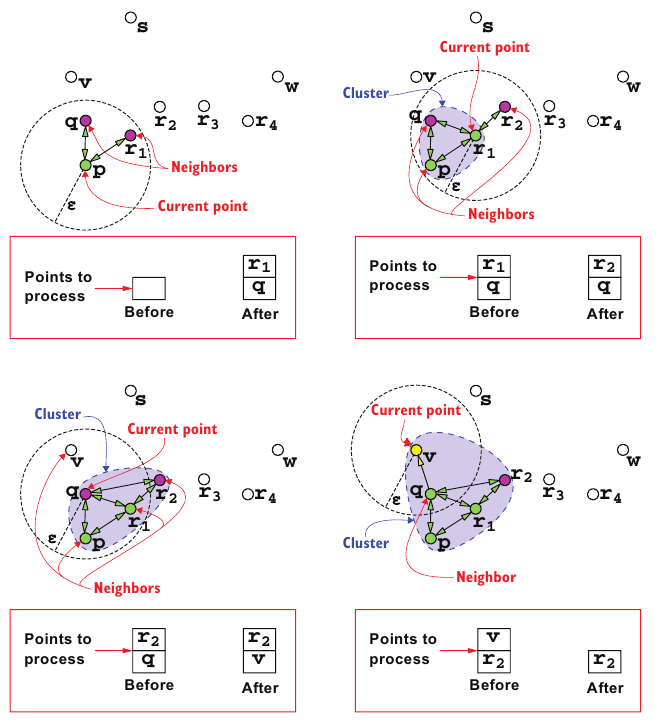
На рисунке 12.10 приведено несколько шагов основного алгоритма. Когда базовые точки обработаны (первые три шага на рисунке) все их неоткрытые соседи добавляются к текущему кластеру в набор (не в очередь) точек для обработки. И наоборот когда текущая точка обработана и не является базовой точкой, например v на последнем шаге, тогда никаких дальнейших действий не требуется.