
Что такое Forth
В двух словах, Fort это комбинация компилятора и интерпретатора. Компилятор транслирует исходный код не в машинные кода так как мы видели в предыдущем примере, но в инструкции для «виртуальной» машины, который мы будем называть «pcode». Таже идея используется в Java и Python и в современных динамических языках.
Однако в Forth, мы программируем на уровне pcode, что мы могли практически называть языком ассемблера для виртуальной машины. Но это язык, который может расширять интересными способами, что дает придает ему довольно динамический характер.
С Forth вы играете, что я хотел бы назвать «Фрагменты вычислений» называемыми «Словами», которые манипулируют стеком данных и соединяются вместе для создания (компиляции) новых «слов», которые в свою очередь делают тоже самое только на один уровень выше.
Хотя язык больше на используется широко, у него есть возможности что делает изучение полезным. Язык обладаем великолепным минимализмом, который можно оценить только при изучении примера кода.
Форт был хорошим компромиссом для относительно легкого создания программ в сравнении с ассемблером, что потребовало на удивлении мало памяти и могло бы выполняться на удивление быстро. Я построил систему с резидентным компилятором, интерпретатор и код приложения Forth с параллельными потоками занимает несколько килобайт компьютерной памяти и работает примерно вдвое медленнее той же программы, написанной на ассемблере.
Согласно Википедии, Forth все еще используется для таких вещей как загрузчики, встроенные системы и космические приложения. Существует активная реализация проекта GNU.
В этой главе мы создадим небольшую систему Forth компилятор/интерпретатора на Python и исследуем ее в деталях. Наша реализация очень проста и мала. Числа (плавающие и целые) являются единственным типом данных и ввод/вывод осуществляется только через терминал.
Позднее, мы кратко посмотрим на приложение упомянутое выше, автоматическая система управления для газетной почты. Сядьте удобнее и наслаждайтесь поездкой.
Несколько слов о правилах цитирования. Если я использую слово заглавными буквами, — это слово Форт. Наш Форт не чувствителен к регистру, как вы увидите, но традиционно Форт программы писались в верхнем регистре. Слова в смешанном регистре являются сущностями в коде Python. TOS находится на вершине стека. Другие слова будут цитироваться, если они обозначают сами себя.
Использование стека данных
Стек данных — это главная функция, как плита на вашей кухне. И поэтому мы манипулируем им напрямую, мы должны пойти на небольшой компромисс для языка. Мы должны строится покомфортнее в работе с постфиксом.
Давайте перейдем к примеру. Нажми здесь для скачивания файла forth.py

Здесь мы вычисляем произведение двух сумм (5+6)*(7+8) которые в обычной инфиксной записи требуют, чтобы суммы были расположены в скобках чтобы гарантировать, что умножение следует за сложением. Теперь в префиксной нотации, подобной той, что используется в языке Lisp, еще необходима одна пара скобок (* (+ 5 6) (+ 7 8)). Но в Форт мы используем постфиксную запись и необходимость в скобках просто отпадает. Операторы размещаются просто в месте, где они используются в вычислениях.
(Примечание. Если случайно вы знаете Японский, то вы знаете, что вещи в постфиксе не так уж и ненатуральны).
Мы можем увидеть, что происходит немного более яснее при использовании Форт слова «dump» для отображения стека данных в любой момент времени. Давайте немного углубимся и покажем стек данных после каждой простой операцией.

Надеюсь, что это сделает его кристально чистым.
Встроенные примитивные слова для манипуляции стеком данных
Наряду с сложением, вычитанием, делением и умножением есть другие основные встроенные слова, которые также управляют стеком. * DUP дублирует вершину стека (TOS) * SWAP меняет два верхних элемента. * DROP извлекает TOS и исключает его. * «.» извлекает и печатает значение на вершине стека TOS. * «=» извлекает два верхних элемента, сравнивает их и сохраняет 1 на стек если они равны или 0 если нет.
Все это можно комбинировать хитроумными способами. Здесь два примера.

Вот код Python для некоторых основных функций времени выполнения в файле forth.py. Наш стек данных просто называется «ds» и представлен в виде списка. Мы используем для списка, метод «append» чтобы поместить элементы в стек и метод «pop» чтобы получить (удалить) верхний элемент. Каждое основное слово – это маленькая функция с двумя аргументами. Эти функции не используют аргументы, но мы позже увидим другие функции времени выполнения, которые их используют.

Некоторые из них могли, конечно, быть выполнены более эффективно, но мы выберем ясность. Обратите внимание на порядок операций, особенно с делением и вычитанием. Также с оператором деления мы используем Python «/», поэтому если хотя бы один аргумент является числом с плавающей запятой, результат будет с плавающей запятой. Если оба являются целыми числами, тогда выполняется целочисленное деление.
Ссылка на каждую из этих функций находится в таблице поиска «rDict» которая сопоставляет такие операторы как «+» с их функцией (rAdd). Эти простые словарные записи.
Определение новых слов
Давайте определим слово NEGATE для замены TOS его отрицательным значением. Каждое определение слова начинается с «:» за которым немедленно следует слово, которое мы хотим определить. Затем все что следует до закрытия «;» становится телом определения. Итак, давайте определим NEGATE и протестируем его и затем сделаем тоже самое для SQR.

Компиляция слов в Pcode
Первым шагом в компиляции есть лексический анализатор, который в Forth действительно прост. Функция «tokenize» сначала удаляет полосы комментариев, которые в этом маленьком компиляторе является чем-то вроде «#» до конца строки. Затем функция просто разделяет текст на список слов, разбивая его по пробелам. Давайте посмотрим на это из командной строки Python.

Когда компилятор не находится в середине определения нового слова или как мы увидим позже, создавая управляющую структуру, она работает в так называемом «немедленном режиме». Это означает что одно слово будет скомпилировано и возвращено.

Обратите внимание как запущенная функция компиляции автоматически запрашивает от нас ввод данных.
Скомпилированный код помещается в списках. Число целое или с плавающей запятой компилируется в «rPush» числа в стек данных. «+» и «.» просто компилирует их соответствующие функции времени выполнения. Давайте посмотрим на функцию «compile» Python.
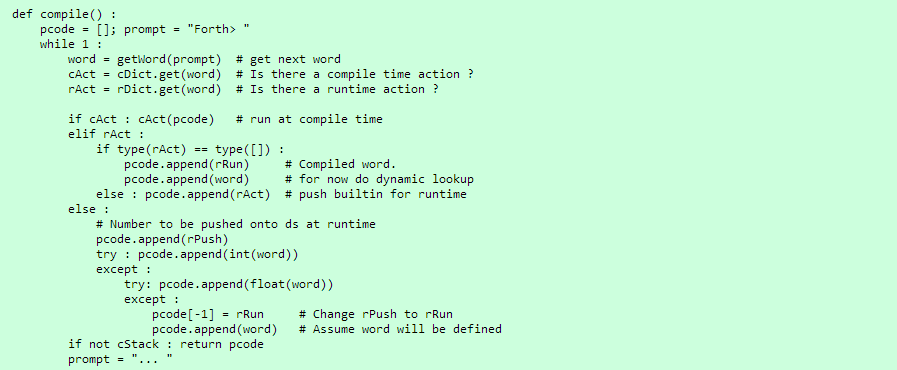
Часть этого может быть немного не ясным. По сути, мы получаем следующее слово используя «getWord» которая если необходимо больше ввода, запросит его. Эта функция «compile» определяет является ли подсказка «Forth>» or «...». Мы увидим, как это используется через некоторое время. Если название слова — это базовое действие времени выполнения в «rDict», то оно транслируется в вызов этой функции. Если слово может быть преобразовано в целое или число с плавающей точкой, тогда «rPush» (тоже встроено) становится переводом, за которым следует фактическое число, которое поместится в стек данных. В немедленном режиме простой ввод слова будет скомпилирован и возвращен.
Далее, давайте скомпилируем новое слово.

Нет возврата pcode! Но есть интересный побочный эффект.

У нас есть новая запись в rDict которую можно использовать как встроенную

Обратите внимание на функцию «compile» над проверкой cAct в cDict. Она ищет функцию времени компиляции. Эти функции являются вспомогательными для процесса компиляции. Оба «:» и «;» являются словами времени компиляции. Давайте посмотрим на соответствующие им функции Python.

Вы можете заметить, что запись помещена в cStack с «:» и позже снимается с помощью «;». Слово «:» получает метку из ввода и если оно не было доступно вам было бы подсказано «...» ввести его. Эта метка сохраняется для «;» слова чтобы соединить с компилированным кодом и сделать запись в rDict. Как только это произойдет код стирается. Сейчас cStack не пустой, компиляция начатая с «:» должна перейти к соответствию «;». Тогда мы говорим, что компилятор запущен в отложенном режиме «deferred mode».
Итак, давайте теперь посмотрим на другие группы слов, которые также используют cStack вызываю отложенную компиляцию.
BEGIN ... UNTIL управляющие структуры
Слова BEGIN и UNTIL создают итеративный цикл. UNTIL будет снят с TOS и, если равен нуль, будет возвращено управление слову следующим за BEGIN. Вот пример

Мы начинаем с помещения числа 5 на вершину стека, печатаем его, вычитаем 1 и повторяем до нуля. Обратите внимание на использование слова DUP дважды, необходимо сохранить число так как мы не только считаем его, но также печатаем его и проверяем на ноль.
Оба слова BEGIN и UNTIL являются словами времени компиляции. Здесь соответствующие им функции Python

BEGIN не генерирует код. Он просто помещает адрес (len(pcode)) следующего слова в стек управления и тем самым переводит компилятор в отложенный режим. UNTIL проверяет наличие совпадения BEGIN и генерирует вызов rJZ (переход, если ноль) обратно на сохраненный адрес. Во время выполнения rJz снимет TOS и сделает переход если он равен нулю.
Вот хорошее «Forth-like» слово определение для вычисления факториала TOS. Этот код был сохранен в файле «fact1.4th».

Обратите внимание на DUMP посередине для отладки. Давайте запустим его.

IF, ELSE, THEN управляющие структуры
Формат этой структуры управления

Снова, если вы немного знакомы с японской грамматикой, этот порядок не покажется ужасно неестественным. Давайте посмотрим на помощников времени компиляции для этих слов

Это должно выглядеть привычным после изучения кода времени компиляции для BEGIN и UNTIL.
IF сгенерирует rJz для ELSE если он есть, или если нет тогда THEN. ELSE завершит переход для IF и установит безусловный переход, который будет завершен THEN. THEN должен завершить любой необходимый прыжок из IF или ELSE.
Вот второе факториальное определение слова. Вместо использования итерации с BEGIN и UNTIL мы используем рекурсию, тема, которую мы будем обсуждать позже более глубоко. И вместо того, чтобы использовать флаг для установления конечной точки вычисления, мы будем использовать нашу новую команду IF, THEN.

И снова DUMP был стратегически размещен для наблюдения за действием.

Variables, Constants and the Heap
Наступает момент, когда необходимо хранить данные вне самого стека данных. Мы, возможно, захотим более удобно держать наши значения независимо от изменяющегося стека данных, и мы можем захотеть хранить данные в одномерных или многомерных массивах.
Forth системы выделяют для этой цели область памяти и содержат несколько встроенных функций которые используются для построения слов которые в свою очередь создают другие слова. Это довольно аккуратно.
Во-первых, давайте посмотрим на сами встроенные функции. В нашей модели «heap» куча — это простой список из 20 целых чисел. Очевидно, это не предназначено для реального времени.

Интересно что rCreate и rAllot являются словами времени выполнения. Когда rCreate запускается компилятор находится в немедленном режиме и следующее слово на входе (Не в pcode) будет определяемым словом. Определенное слово времени выполнения будет простым местом зарезервированного адреса в куче в стеке данных, продвижение кучи heapNext что бы быть готовым к будущему CREATE. Давайте посмотрим на пример. Мы будем использовать forth.main для компиляции и выполнения нашего Forth-кода.

Здесь мы создали три новых слова V1, V2 и V3. У каждого есть соответствующий адрес в куче и когда они запускаются каждый заталкивает свой адрес. Заметим, что «space» между V2 и V3 из-за ALLOT использованного при создании V2.
Вот как мы используем эти места в куче. Две встроенные функции “@” и “!” извлекают и устанавливают слова в кучу. Давайте немного поиграем с этим

И так мы создали 2 простые переменные (V1 и V3) и массив из 3 слов V2. Вернувшись в Python, мы видим, что куча изменяется и также определение времени выполнения для одной из переменных.
Другая полезная встроенная функция «,» которая извлекает TOS и помещает в кучу в следующем свободном месте. Это можно использовать вместо ALLOT для инициализации переменных нулем.

Наконец есть встроенный DOES> что работает вместе с CREATE внутри определения. Он принимает все следующие слова до закрытия «;» и добавляет их к записи rDict для только что созданного слова. Сначала рассмотрим это определение и использование как CONSTANT

Это нормально, но ничего не запрещает вам просто «!» присвоить thisYear или другое значение. Это же самое что и любая переменная. Но если вместо этого сделаем следующее

Затем вы можете увидеть, как вызов rAt был присоединен к выполнению thisYear. Нет необходимости использовать «@» для извлечения этого значения и «!» и не может быть использован для изменения его значения.
С помощью этих встроенных функций, не сложно делать массивы в том числе многомерные. Мы можем даже сделать примитивную структуру (наподобие СИ) назначая константы для смещения полей.
Как СИ, однако, здесь не так много защиты памяти. Если ссылка массива выходит за пределы, она просто запишете что-то еще. Конечно, в нашей модели это останется в нашей куче, но в адаптации СИ кода даже это было бы потеряно.
Мы закончим этот раздел с финальной программой вычисления факториала, на это раз с использованием переменных. Этот код больше похож на традиционный код, хотя и в постфиксе.

А сейчас давайте запустим его

Поскольку наша модель встроена в Python, мы унаследуем его милый хороший автоматический переключатель на длинные числа.
Обратите внимание что переменные “m” и “answer” определены вне определения “fact”. У нас нет закрытых локальных переменных в определении.
Другие вопросы
Как упоминалось ранее, Forth может быть очень эффективным с памятью и процессорным временем. Рассмотрим следующие фрагменты ассемблерного кода PDP-11. Это воссоздание нашего небольшого фрагмента первого Forth выражения 5 6 +.

Это должно выглядеть несколько знакомым по модели ассемблера в предыдущей главе. У нас есть стек данных на верху, немного «threaded» кода посередине и 3 встроенных функции. Потоковый код (название очевидно будет через минуту) по сути такой же как наш массив “pcode” в модели Python. Машинный регистр r3 это на ш индекс “p” для следующего слова в pcode. Программный счетчик, регистр PC переключается между встроенными функциями. Инструкция «jmp @(r3)+» загружает программный счетчик из слова памяти индексированного r3 а затем увеличивает r3 чтобы он указывал на следующее слово. Выполнение программы проходит через многопоточный код из одной встроенной функции (rPush) в следующую (rAdd). Регистр r4 является индексом ds. На PDF-11 стек рос вниз, и более низкие машинные адреса были выше в стеке. Инструкция «mov (r3)+,-(r4)» помещает следующее слово в потоке (5 say) в стек данных, сначала уменьшая r4 до более высокого положения в стеке.
Сейчас если бы мы написали это на ассемблере, мы могли бы сделать следующее

Но если сложить использованную память и циклы выполнения, только инструкции «jmp @(r3)+» которые как (иглы) сшивают вместе код. Эти прыжки оставляют очень мало накладных расходов.
В начале 1980-х я разработал систему управления процессами для газетной почтовой службы, которая отслеживала пачки газет на конвейерных лентах. Каждая связка имела определенное обозначение транспортира, по которому она доставлялась в загружаемый грузовик. Мы собрали маленькую Forth систему менее чем из 1000 строк ассемблера. Это система была параллельной и имела специальное слово чтобы один поток мог передать контроль управление процессором другому. Как и сам Forth это приложение было на маленькие кусочки, сшитые вместе. Например, один поток pcode отслеживал ввод с клавиатуры с одного из терминалов. Другой вывод сообщений на все экраны, которые включали эхо ввода с любой клавиатуры. Другие потоки будут обрабатывать датчик на ремне и ли обновлять световой дисплей. У каждого потока был свой собственный стек данных, но они разделяли переменные в куче и конечно же определение слов.
Проблем с блокировкой не было, потому что потоки сами передавали управление только тогда, когда это было безопасно. Такая система была возможна, потому что пропускная способность была только ограничена скоростью человека.
Последняя точка. Мы использовали рекурсию во втором примере факториала. Это необычно для Forth. Обычно слово должно быть определено до того, как оно будет использовано в другом определении. Но в нашей функции компиляции последнее «except» позволяет на построить rRun для неопределенного слова с предположением что оно будет определено до того, как оно будет фактически использовано. Но это в свою очередь приводит к другим проблемам. Наш rRun запускает слово динамически, то есть ищет определение в rDict непосредственно перед запуском. Большинство Forth не стали бы этого делать. Это дорого, когда вычисления для большинства слов обычно настолько малы. Таким образом чем следовать за записью pcode “rRun” с именем слова, это будет ссылка на слова pcode и поиск в словаре будет исключен. Это также имеет интересный смысл. Если вы переопределите слово, которое использовалось в определении других слов, те другие слова не изменят своего поведения. Они по-прежнему привязаны к старому коду. Программист вполне может найти это неожиданным.
Copyright © 2015-2021 Chris Meyers and Fred Obermann